
 We tested the Hydor Seltz D 6000 pump over a long period of time, and discovered that it works flawlessly and it has a great quality/price relationship.
We tested the Hydor Seltz D 6000 pump over a long period of time, and discovered that it works flawlessly and it has a great quality/price relationship.
The Hydor Seltz D6000 is one of the few pumps that still use an alternate current, like the Rossmont Riser 3200 that we tested last year (review), and the Rossmont Riser RX5000 that we are actually currently testing. The main features are that they don’t have a dedicated app and they do have a very low price.
We, as always, measured hydraulic head, flow rate, and consumption. We obtained 6 couples of values in correspondence with every possible level.
For the hydraulic head we used the usual static method. For the flow rate we used the flow meter DigiFlow 6710M and for the consumption we used the RCE PM600.
Declared technical characteristics of the Hydor Seltz D6000
| European Version 230 V – 50 Hz | |
| Flow rate: | 6.000 l/h |
| Consumption: | 60 watt |
| Hydraulic head: | 4,2 meters |
| Length: | 19,5 cm |
| Depht: | 8,9 cm |
| Height: | 11,9 cm (the body only) |
| Price: | 125,00 euro ($136 USD) |
| Value of reference: | 12.600 l*m/s |
 The Hydor Seltz D6000 has an electric efficiency of 100 liters of flow rate for each watt and an economic efficiency of 48 liters per second per euro and at the end a reference value of 12.600 l*m/s.
The Hydor Seltz D6000 has an electric efficiency of 100 liters of flow rate for each watt and an economic efficiency of 48 liters per second per euro and at the end a reference value of 12.600 l*m/s.
The relationship of quality to price is extremely high. The cost is, in fact, very low; for 125 euro we can buy a pump that is adjustable to six levels, with very important values of flow rate and hydraulic head. But this is just what has been declared, now let’s see what we measured and how it fits into our chart with the values we’ve found for all the other pumps we’ve tested. Until yesterday this is the pump I used in my aquarium.
The construction
The pump is very simple. The body is tapered and roundish, and a very big grid in the anterior part. The livery is bicolor, black and amaranth.

The pump hinges on the inferior saddle, where there are the some rubber tips that help to reduce out noises and vibrations. The input and the output of the water can be of 21, 26 and 32 mm depending on the hoses you keep or cut. 
We immediately disassembled the pump to see its impeller. 
We took off the cover shell, revealing this impeller with 6 curved and protected blades. 
The impeller itself isn’t so small, but the magnetic body is quite short. It also has a o-ring in the internal part.
How to use the Hydor Seltz D6000
The main feature of this pump is that it’s AC. But you can set hydraulic head and flow rate through a controller and 6 available couples of values that correspond to the engine speed. Moreover, there’s a button that stops the pump for 5 minutes. 
Hydraulic head test
The first test we did concerned the hydraulic head. As you may know the hydraulic head is the pump’s capacity to raise the water over a certain level. In order to do this test we measured the level of water reached inside the rubber tube.
The following picture is from our archive to show you how we work.

As usual, we turned on the pump, we waited about 10 minutes for the pump to stabilize, and then we tested the level six times. 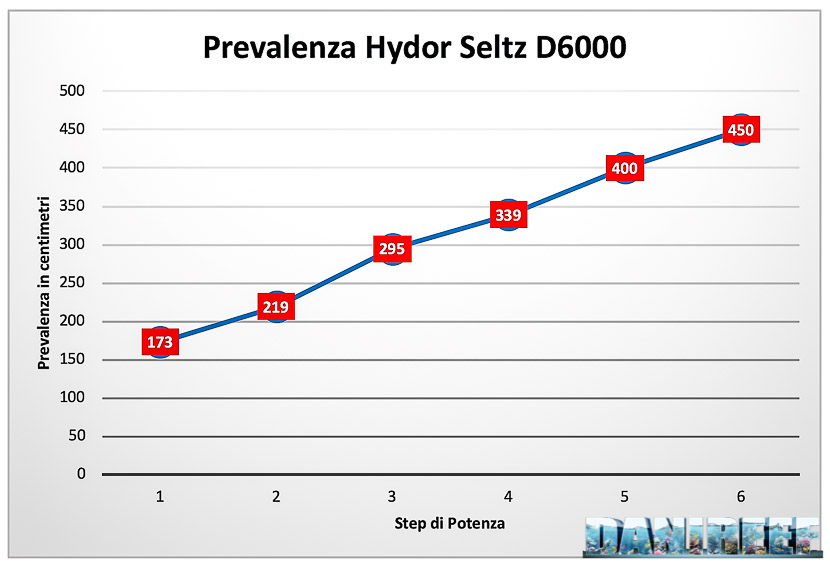
We measured a maximum head of 4,50 meters versus the declared 4,2 meters.
The gap between the hydraulic head declared and measured is +7%. A very good result. The curve we recreated is quite linear.
Flow rate test
Testing the flow rate was easy thanks to the flow rate meter DigiSavant DIGIFLOW 6710M. The first thing we did was connect the tubes to our meter. We tried to make the meter perfectly join the exit of the pump. The measurement is expressed in liters/minute, so we just had to multiply the result by 60 to obtain liters per hour.
Obviously, remember that this measurement is valid for the conditions in which we did our tests. The connecting tube could have introduced some losses in the system.
We measured the flow rate for each step of power in order to have a complete distribution of the flow rate.
These number, traduced in liters per hour, lead us to the following chart: 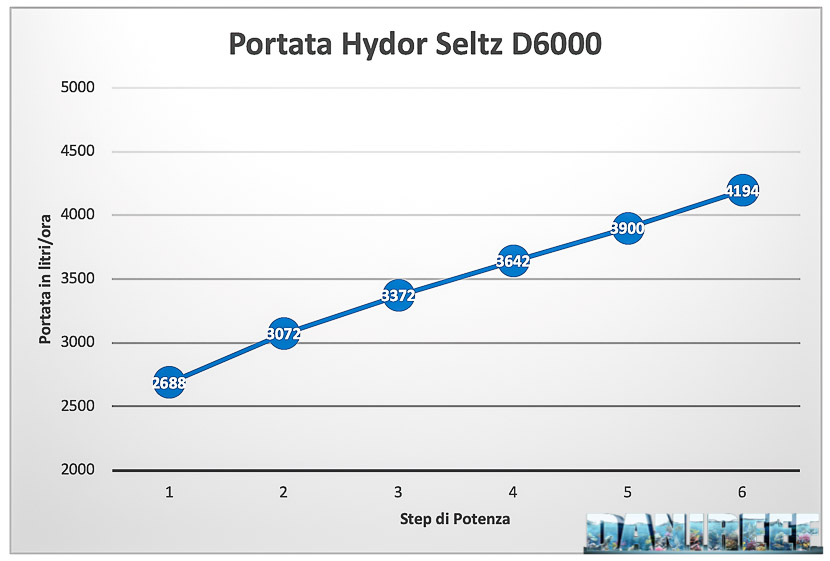
The maximum flow rate head was 4.194 l/h (that is 69,9 l/m*60), well below the declared 6.000 l/h. So the pump reached the 70% of the declared value in our test’s conditions. A little too low for what we were expecting, but if you go to see our other reviews, very few pumps actually reach the declared values for the flow rate. Considering this, we can say that this 70% is just below average, and we even tried pumps with flow rate less than 50% of declared…
When you use a return pump be careful of the aspects that may lower the flow rate, even drastically. Use the larger hose supplied. Use a sufficiently large tube. The tube should always be as short as possible, and avoid 90° curves. Otherwise the flow rate will decrease significantly.
Characteristic curves
The distinctive curve is that specific curve that links the various values of flow rate and hydraulic head. You can’t do this without the proper equipment. We could have done this for the 6 steps we measured, but we believe that the qualitative comparison would be enough. We only linked the two ends of flow rate and hydraulic head, both the measured and the declared ones. 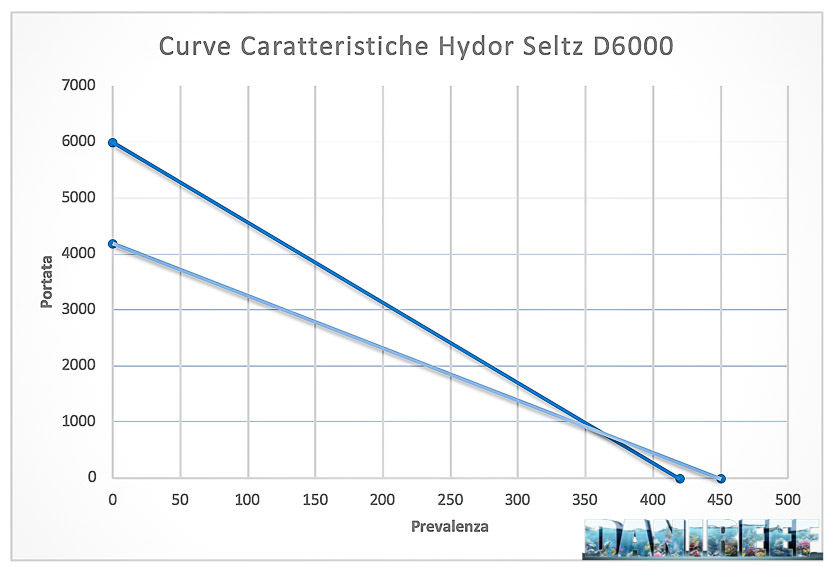
Now you can see how the difference between the declared value (the top curve) and the measurement is practically negligible. As you can see on the left, the difference is larger for the flow rate than the hydraulic head. The area between the two lines is what we didn’t have but we expected given the project. Obviously the project curve is the top one. On the right, where there’s the hydraulic head, we have the opposite.
In theory, if you put yourself at the hydraulic head value you need, for example 200 cm, you should draw a line at the value of 200, see where this line crosses the distinctive line and read the corresponding flow rate value. With the Hydor Seltz D6000 at 200 cm of hydraulic head you should have a flow rate of about 2400 l/h against the declared 3200. In aquarium the situation will be even worse because you have to add the friction of the tube and the curves.
In order to calculate the flow rate of your aquarium here’s a useful link with calculator integrated: automatic calculus of the return pump (italian).
Energy consumption test
The collection of data about the consumption has been made possible by the useful device RCE PM600. The result is already given in watts. 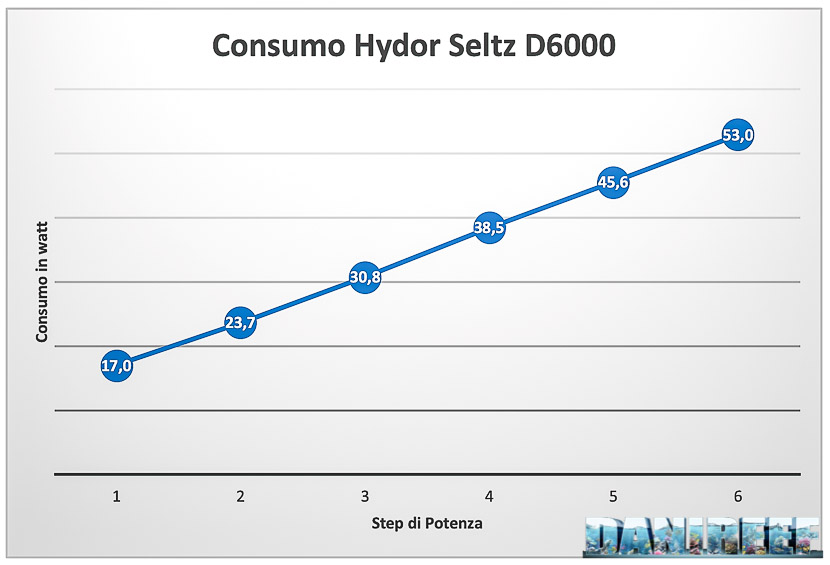
The maximum declared consumption of the Seltz is 53 watts. According to our measurements the consumption is about 12% below the declared value. A difference that comes to our advantage.
Considering a consumption of 53 watt, and a cost of 0,27 euro per kwh, we could use this pump continuously for a whole year, at its maximum with a consumption of 464 kwh, having a cost of 125 euro per year, or 10,4 euro per month.
Given the dimensions of the pump and especially its flow rate level, we couldn’t do our noise test. We can affirm that the pump is very silent; we’re currently using it in aquarium and we would have noticed any noise. But at its maximum the sound is rather acute, even if I only hear it when the door is open.
Our comments
Remember, an adjustable pump is the best thing you can have in sump, for a lot of reasons. The option to change the power to make it adapt to the conditions of the aquarium is the best.
For example, when you change the water in your aquarium without a bulkhead in the sump, you can decrease the the flow rate of the pump in order to have less exchange between aquarium and sump. In this way you can have less water in the aquarium without turning off the returning pump. In fact, when lowering the flow rate of the pump, the level in the sump tends to increase while the one in the aquarium tends to decrease, so, when taking out water from the aquarium, you don’t risk leaving the pumps dry.
Unluckily if you have a sump with a bulkhead this trick isn’t possible. 
The page of the conclusions is really dense, in part because of the comparison that we did with similar pumps we’ve already tested.
The comparison with other pumps
The chart you’re going to see is very interesting. It’s the result of the values obtained from other pumps, Eheim, Tunze, Sicce, Corallinea, Waveline, Ecotech Marine, and Rossmont, that you can check anytime on our page of reviews. They’re ordered by the reference value of the pump, which is the product of the flow rate for the hydraulic head divided by two. In this way the area between the two sizes is obtained. 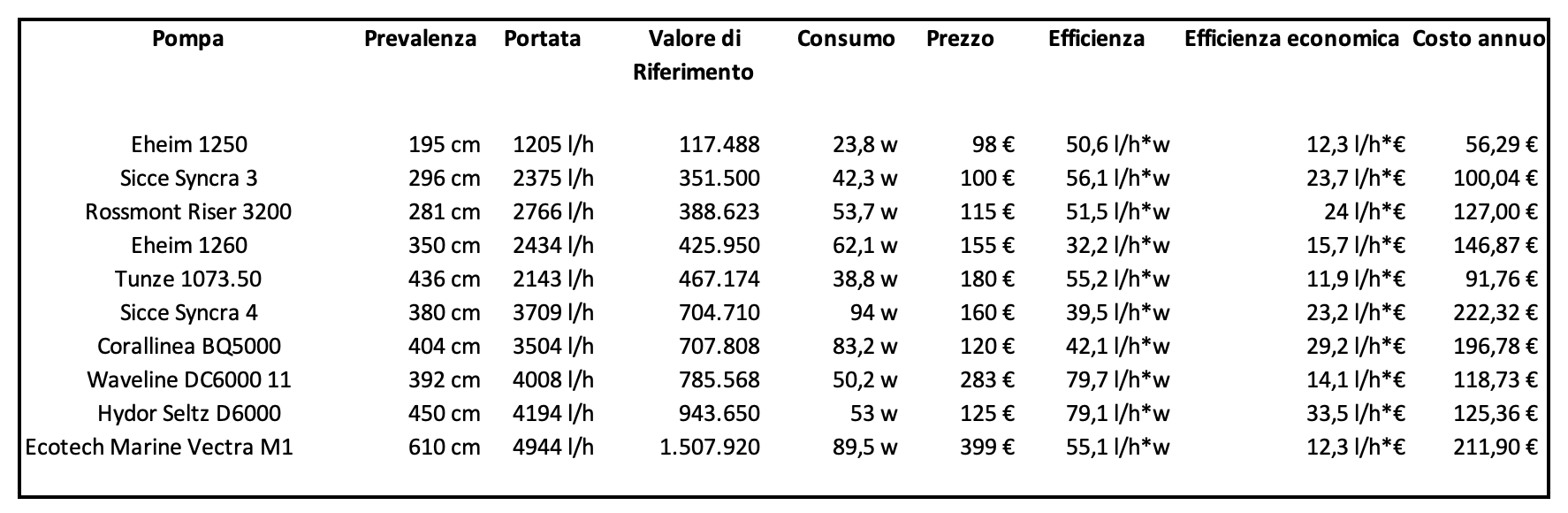
In the chart we reported the values of some pumps tested here on Reefs.com. In particular the last five variable flow pumps, the Tunze 1073.050 (review), the Corallinea BQ5000 (review), the Waveline DC6000 (review), the Vectra M1 (review), and the Rossmont Riser 3200 (review).
From the chart, we can see that economically speaking, or the relationship of flow rate/euro, the Hydor is always the most convenient, followed by the Rossmont Riser 3200 and the Chinese Corallinea BQ5000. For the technical efficiency, considering only the maximum values, the Waveline DC6000 wins very little against the Seltz D6000. Then, as the couple of values that you need matches with this pump, it’s practically first for technical and economic efficiency out of any pump that we’ve tried. And, in addiction, it’s immediately adjustable, even if not sophisticated.
Relationship with the declared data
Now let’s see the relationship with the data declared from the builder.
Hydraulic head
| pump | hydraulic head | measurement | difference |
| Hydor Seltz D6000 | 420 cm | 450 cm | + 7 % |
The maximum hydraulic head has a noticeable gap, but to our advantage.
Flow rate
| pump | flow rate | measurement | difference |
| Hydor Seltz D6000 | 6.000 l/h | 4.194 l/h | – 30 % |
The gap between flow rate measured and declared is close to 30%, a result, unfortunately, similar to other options.
Energy consumption
| pump | consumption | measurement | difference |
| Hydor Seltz D6000 | 60 w | 53 w | – 12 % |
The energy consumption is lower than 12%, more or less. Best for our aquarists.
Closeness to the declared data
Finally, as a term of comparison, we can use a match value on the base of the declared data for flow rate, hydraulic head, and consumption.
| pump | hydraulic head | flow rate | consumption | Final value (absolute) |
| Hydor Seltz D6000 | 107 % | 70 % | 88% | 88 % |
If you want to know if the pump is right for you, I suggest taking a look at these articles:
- How to choose the right return pump for marine aquarium
- Automatic calculation of the flow rate of the return pump (italian)
Conclusions
The reference value of the Hydor Seltz D6000 at its maximum power is 943.650 l*cm/s, where the reference value of the comparison declared is 1.260.000. Remember that the reference value is the area between the values of flow rate and hydraulic head, exemplified by their maximums. So we’re going to do this operation: (flow rate x hydraulic head)/2.
The loss of the 30% actually is an average value, and all but one competitor has the same percentage.
Anyway, we have to consider what the pump obtained, not what it meant to obtain. In fact we have to choose our pump based on if what has been measured matches our needs, while maybe also being a little cheaper.
And the Hydor Seltz D6000 has an incredible quality/price relationship. Its economic and technical efficiency are impressive, it’s adjustable, and the price isn’t excessive. What else do you want from a pump? 









Was it quiet?
Yes a lot, currently it is under my yank
Can you please tell me how to use the hydor d 6000 pump as I can’t get it to run continually it keeps stopping and starting so how do I make it run all the time any help would be helpful many thanks
I think your pump is broken…
Hi I have one of your hydor seltz 6000dc pumps and I would like to know if the screws that hold the front housings are safe in a reef tank if you could let ne know that would be great many thanks
Hi Garry, unfortunately the Hydor is not mine 😉
Anyway I haven’t had any issues with the screws. But I know some friends of mine have has some oxidising on the screws. It’s nothing to worry about, only you have to do some maintenance.